继“理解卷积神经网络的利器:9篇重要的深度学习论文(上)”文章,本文继续介绍过去五年内发表的一些重要论文,并探讨其重要性。论文1—5涉及通用网络架构的发展,论文6—9则是其他网络架构的论文。点击原文即可查看更详细的内容。
5.Microsoft ResNet(2015)
现在,将一个深度卷积神经网络的层数增加一倍,再增加几层,也仍然不可能达到2015年微软亚洲研究院提出的ResNet架构的深度。ResNet是一种新的包含152层的网络架构,它使用一个特殊的结构记录分类、检测和定位。除了在层数方面进行创新外,ResNet还赢得了2015年ImageNet大规模视觉识别挑战赛的冠军,误差率低达3.6%(在现有的技术水平上,误差率通常在5-10%)
残差块
残差块的原理是,输入x通过卷积-残差函数-卷积系列,得到输出F(x),然后将该结果加到原始输入x中,用H(x)= F(x)+ x表示。在传统的卷积神经网络中,H(x)=F(x)。因此,我们不只计算从x到F(x)变换,而是要计算H(x)= F(x)+ x。下图中的最小模块正在计算一个“增量”或对原始输入x做轻微改变以获得轻微改变后的表示。作者认为,“优化残差映射比优化原始未引用的映射要容易。”
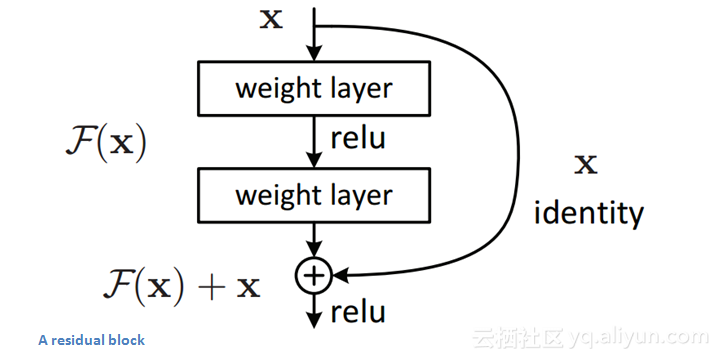
残差块可能比较有效的另一个原因是,在反向传播的后向传递期间,由于加法运算可以作用于梯度,梯度将会更容易地通过残差块。
主要论点
1.“极端深度” - Yann LeCun。
2.包含152层
3.有趣的是,仅在经过前两层之后,将数组从224*224压缩到56x56。
4.在普通网络中,单纯的增加层数会导致更高的训练和测试误差(详细请看论文)。
5.该模型尝试构建了一个1202层的网络,可能是由于过拟合,测试精度较低。
重要性
3.6%的误差率!这一点足够重要。ResNet模型是目前我们所拥有的最好的卷积神经网络架构,也是残差学习理念的一个伟大创新。我相信即使在彼此之上堆叠更多层,性能也不会再有大幅度的提升了,但肯定会有像过去两年那样有创意的新架构。
6.基于区域的卷积神经网络:R-CNN(2013年);Fast R-CNN(2015年); Faster R-CNN(2015年)
有些人可能会说,R-CNN的出现比以前任何与新网络架构有关的论文都更具影响力。随着第一篇论述R-CNN的论文被引用超过1600次,加州大学伯克利分校的Ross Girshick团队创造出了计算机视觉领域最有影响力的进展之一:研究表明Fast R-CNN和Faster R-CNN更适合对象检测,且速度更快。
R-CNN架构的目标解决对象检测问题。现在,我们想对给定的图像上所包含的所有对象绘制边界框,可分为两步:候选区域的选择和分类。
作者指出,任何类不可知候选区域方法都应该适用。选择性搜索专门用于R-CNN,它能够产生2000个不同的最有可能包含指定对象的区域,候选区域产生后,会被“转换”为图像大小的区域,送入一个训练好的卷积神经网络(在这种情况下为AlexNet),为每个区域提取特征向量。然后,这组向量作为一组线性支持向量机的输入,这些线性支持向量机对每个类进行训练并输出一个分类。向量也被送入边界框回归器以便获得最准确的位置坐标。最后,使用非极大值抑制来抑制彼此具有明显重叠的边界框。
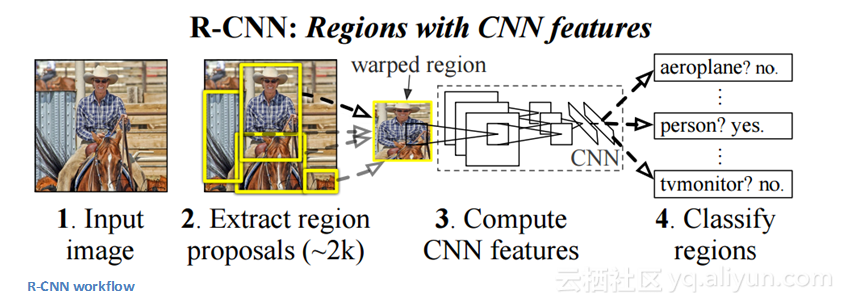
Fast R-CNN
对原始模型进行改进原因有三:模型训练需要经历多个步骤(ConvNets→支持向量机→边界框回归器);计算成本很高,运行速度很慢(R-CNN处理一张图像需要53秒)。为了提高运行速度,Fast R-CNN共享了不同候选区域之间卷积层的计算,交换了候选区域的生成顺序,同时运行卷积神经网络。在这个模型中,图像图像首先送入卷积网络,然后从卷积网络的最后一个特征映射获得候选区域的特征,最后被送入全连接层、回归以及分类头部。
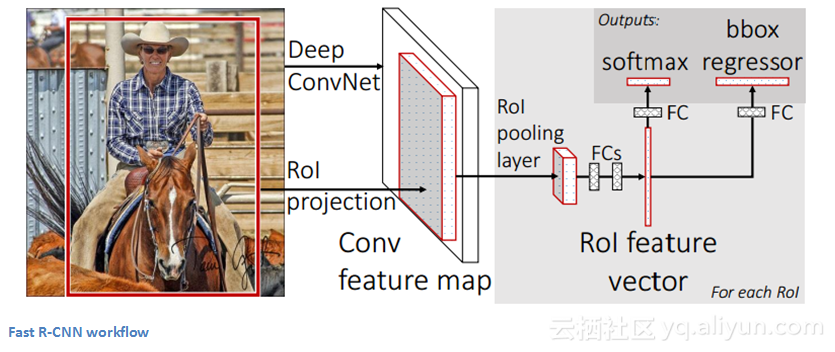
Faster R-CNN
Faster R-CNN致力于将R-CNN和Fast R-CNN比较复杂的训练步骤简单化。作者在最后一个卷积层后插入候选区域生成网络,该网络能够查看最后的卷积特征映射并产生候选区域。后面使用与R-CNN相同的方法:感兴趣区域池化、全连接层、分类和回归头。
重要性
除了能够准确识别图像中的特定对象,Faster R-CNN也能够对该对象进行准确定位,这是一个质的飞跃。现在,Faster R-CNN已经成为对象检测程序的一个标准。
7.生成敌对网络(2014)
据Yann LeCun称,该网络可能是下一重大进展。在介绍这篇文章之前,我们先看一个对抗的例子:将一个经过扰动的图像经过卷积神经网络(已经在ImageNet数据集上训练且运行良好),以使预测误差最大化。因此,预测出来的对象类别有所改变,而该图像看起来与没有经过扰动的图像相同。从某种意义上来说,对抗就是用图像愚弄卷积网络。

这个对抗的例子着实让很多研究人员感到惊讶,并且迅速成为了一个大家感兴趣的话题。现在让我们来谈谈生成对抗网络,它包含两个模型:一个生成模型和一个判别模型。判别器用来确定给定的图像是否真的自数据集,还是人为创建的;生成器用来是创建图像,以便判别器得到训练生成正确的输出。这可以看作一个博弈游戏,打个比方:生成模型就像“伪造者团队,试图制造和使用假币”;而判别模型就像“警察,试图检测假币”。生成器试图欺骗判别器,而判别器努力不被欺骗。随着模型的训练,这两种方法都会得到改进,直到“真币与假币无法区分”。
重要性
这看起来很简单,但为什么我们很看重这个网络?正如Yan Le Leun在Quora中所说的那样,现在判别器已经意识到“数据的内在表示”,因为它已经被训练的能够了解数据集中真实图像与人工创建图像之间的差异。因此,可以像卷积神经网络那样,将它用作特征提取器。另外,你也可以创建很逼真的人造图像(链接)。
8.Generating Image Descriptions(2014)
将卷积神经网络与循环神经网络结合起来会发生什么?Andrej Karpathy团队研究了卷积神经网络与双向循环神经网络的组合,并撰写了一篇论文,用来生成图像不同区域的自然语言描述。基本上,图像经过该模型后输出效果如下:

这真是令人难以置信!我们来看看这与普通的卷积神经网络有何区别。传统的卷积神经网络上,训练数据中的每个图像都有一个明确的标签。论文中描述的模型已经训练了样例,该样例具有与每个图像相关联的文本。这种类型的标签被称为弱标签,其中文本片段是指图像的未知部分。使用这些训练数据,深层神经网络能够“推断出文本片段和他们所要描述的区域之间的潜在关系”(引自论文)。另一个神经网络将图像转换成一个文本描述。让我们分别看看这两个部分:对齐模型和生成模型。
对齐模型
对齐模型的目标是能够将视觉图像和文本描述对齐,该模型将图像和文本转化为二者之间的相似性度量值。
首先将图像输入R-CNN模型,检测单个对象,该模型在ImageNet数据集上进行训练,排名前19位(加上原始图像)的对象区域被嵌入到500维空间,现在在每个图像中,我们都有20个不同的500维向量(用v表示),用来描述图像的信息。现在我们需要关于文本的信息,将文本嵌入到同一个多维度空间中,这一步骤采用双向递归神经网络完成。从更高层次来看,这是为了解释给定文本中单词的上下文信息。由于图像和文本的信息都在相同的空间中,因此我们可以计算内部表示,来输出相似性度量。
生成模型
对齐模型的主要目的是创建一个数据集:包含图像区域和对应的文本。而生成模型将从该数据集中进行学习,生成给定图像的描述。该模型将图像送入一个卷积神经网络,由于全连接层的输出成为另一个循环神经网络的输入,softmax层则可以被忽略。对于那些不熟悉循环神经网络的人来说,该模型可以理解为产生句子中不同单词的概率分布(循环神经网络也需要像卷积神经网络一样进行训练)。

重要性
Generating Image Descriptions的创新之处在于:使用看似不同的循环神经网络和卷积神经网络模型创建了一个非常实用的应用程序,它以某种方式将计算机视觉和自然语言处理领域结合在一起。在处理跨越不同领域的任务时如何使计算机和模型变得更加智能方面,它的新想法为我们打开一扇新的大门。
9.空间变换网络(Spatial Transformer Network)(2015年)
最后,我们来介绍一篇同样很重要的论文,该模型的主要亮点就是引入了一个变换模块,它以某种方式对输入图像进行变换,以便后续网络层能够更容易对图像进行分类。作者不再对卷积神经网络的主要架构进行修改,而是在图像输入到特定的卷积层之前对图像进行变换。这个模块希望纠正姿态规范化(针对对象倾斜或缩放的场景)和空间注意力(在拥挤的图像中关注需要分类的对象)。对于传统的卷积神经网络来说,如果希望模型能够同时适用于不同尺度和旋转的图像,那么将需要大量的训练样例才能使模型进行正确的学习。这个变换模块是如何解决这个问题的呢?
处理空间不变性的传统卷积神经网络模型中的实体是最大池化层,一旦我们知道原始输入数组(具有较高的激活值)中的特定特征,其确切位置就不如它相对于其他特征的相对位置那么重要。而这种新的空间变换器是动态的,它会针对每个输入图像产生不同的变换,而并不会像传统的最大池化那样简简单和预定义。我们来看看这个变换模块是如何运行的。该模块包括:
1.定位网络,将输入数组转化并输出必须使用的空间变换参数。对于仿射变换来说,参数或θ可以是六维的。
2采样网格,这是使用本地化网络中创建的仿射变换(θ)对常规网格进行变形的结果。
3.采样器,将输入特征映射进行变形。
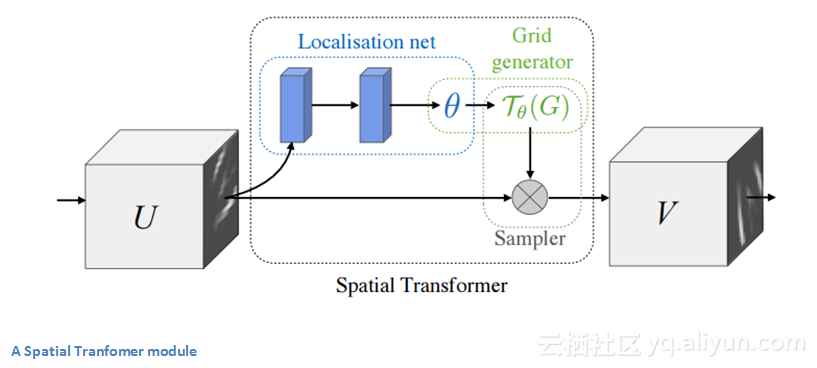
这个模块可以放在卷积神经网络的任何一个节点,基本上可以帮助网络学习如何对特征映射进行变换,从而最大限度地减少训练期间的成本函数。
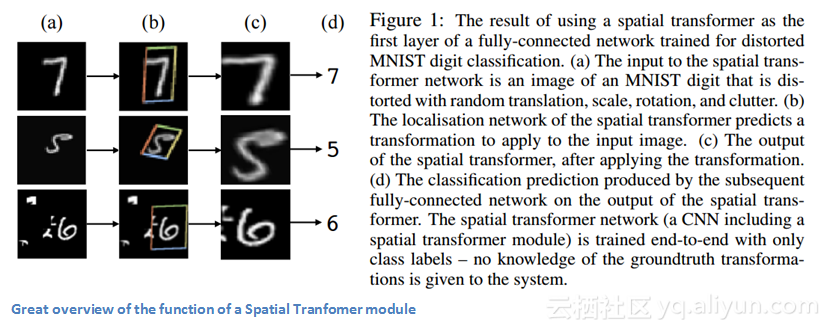
重要性
这篇文章之所以能够引起我的注意,其主要原因就是对卷积神经网络的改进不一定需要对网络的整体架构做巨大的改变,我们不需要再创建下一个ResNet或Inception架构。本文对输入图像进行仿射变换这一思路,使模型更加适用于图像的平移、缩放和旋转。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《A Beginner's Guide to Understanding Convolutional Neural Networks》,译者:Mags,审校:袁虎。


