端上机器学习对于隐私保护、无网环境可用性和智能响应的实现是至关重要的。这需要在设备端使用机器学习算法进行计算,但设备的计算能力有限,这就刺激了算法效率高的神经网络模型和硬件的发展,这些硬件每秒能够执行数十亿次的数学运算,而只会消耗几毫瓦的电量。最近谷歌发布的 Pixel 4 就例证了这个趋势,它附带了 Pixel 神经核心这个硬件单元,并采用了 Edge TPU 架构。这个 Edge TPU 是谷歌用在边缘计算设备上的机器学习加速器,它提高了Pixel 4 的用户体验,例如面部解锁、更快的谷歌助理和独特的摄像头功能。类似地,像 MobileNets 这样的算法为移动端视觉应用提供了紧致而高效的神经网络模型,这对机器学习在端上的成功应用至关重要。
今天我们很高兴宣布 MobileNet3 和其对应的由 Pixel 4 Edge TPU 优化过的 MobileNetEdgeTPU 模型及代码正式开源。这些模型是硬件感知AutoML 技术以及架构设计领域的一些最新进展累积而成的重大成果。在移动端CPU 上,MobileNetV3 比 MobileNetV2 快两倍,而精确度相当,这推动了最先进的计算机视觉网络技术的进步。在 Pixel 4 Edge TPU 硬件加速器上,MobileNetEdgeTPU 有了更进一步的提升,在改进了模型精度的同时还降低了运行时间和能耗。
构建 MobileNetV3
与之前手动设计的 MobileNet 模型版本相比,MobileNetV3 通过 AutoML 在搜索空间里寻找最好的架构,这个搜索空间是针对移动端计算机视觉任务而建立的空间。为了最高效地挖掘这个搜索空间,我们相继引入了两种技术—— MnasNet 和 NetAdapt 。首先,我们使用 MnasNet 来搜索一个大致的架构,其中使用了强化学习方法从一个离散的选项集合中选择最优配置。然后,我们使用 NetAdapt 微调这个架构,NetAdapt 是一种补充技术,能够以较小的精度衰减来减少未充分利用的激活通道。为了在不同条件下都能提供最好的性能,我们分别生成了较大模型和较小模型。
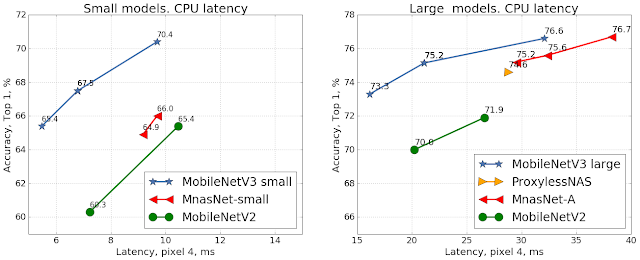
使用谷歌 Pixel 4 CPU,在 ImageNet 分类任务上对移动端模型精度和延时的比较。
MobileNetV3 搜索空间
MobileNetV3 的搜索空间建立在最近架构设计领域的多项创新之上,我们将其适配到了移动端环境。首先,我们引入了一个新的激活函数,命名为 hard-swish(h-swish),它基于 Swish 非线性函数。Swish 函数的主要缺点是其在移动端硬件上效率非常低。所以,相应地,我们使用了其近似函数,它可以有效地表示为两个分段线性函数之积。
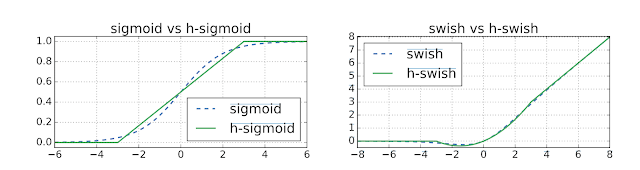
下一步,我们引入了移动端友好的 squeeze-and-excitation 模块,其使用一个分段线性近似函数替换了经典的 sigmoid 函数。
结合 h-swish 和移动端友好的 squeeze-and-excitation(修改了 MobileNetV2 中引入的 inverted bottleneck 结构,我们为 MobileNetV3 构建了一个新的模块单元。
MobileNetV3 扩展了 MobileNetV2 的 inverted bottleneck 结构,增加了 h-swish 和移动端友好的 squeeze-and-excitation 模块作为搜索选项。
以下参数定义了用来构建 MobileNetV3 的搜索空间:
expansion 层的大小
squeeze-excite 压缩的程度
激活函数选取:h-swish 或者 ReLU
每种分辨率模块的层数
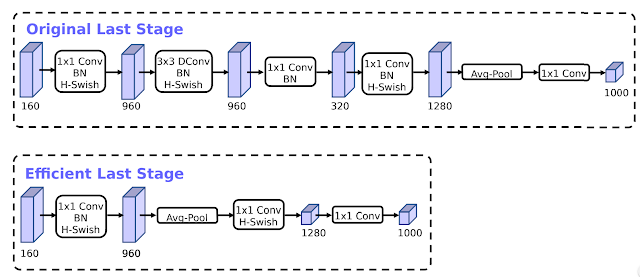
我们还在网络末端引入了一个高效的模块,这将延时进一步减少了 15%。
MobileNetV3 物体检测和语义分割
除了分类模型以外,我们还介绍了 MobileNetV3 的物体检测模型,在 COCO 数据集上,其相比于 MobileNetV2 减少了 25% 的延时,而精度维持在同样水平。
为了优化 MobileNetV3 来实现高效的语义分割,我们引入了具有低延时的分割解码器,命名为 Lite Reduced Atrous Spatial Pyramid Pooling(LR-SPP)。这个新的解码器网络包含三个分支,一个用于低精度的语义特征,一个用于高精度细节特征,最后一个用于轻权重的注意力模型。在高精度 Cityscapes 数据集上,LR-SPP 和 MobileNetV3 的结合使延时降低了 35% 以上。
MobileNet for Edge TPUs
Pixel 4 上的 Edge TPU 架构和 Coral 产品线上的 Edge TPU 很像,但是其为了满足 Pixel 4 上摄像机关键特性的要求而进行了定制化。加速器感知的 AutoML 方法大大减少了为硬件加速器设计和优化神经网络的手动操作。设计神经架构搜索空间是这个方法的重要部分,其围绕着如何选取神经网络操作来改进硬件利用率。尽管像 squeeze-and-excite 和非线性 swish 这样的操作在构建紧致而快速的 CPU 模型方面被认为是至关重要的,但是在 Edge TPU 上的表现并非最优,因此,我们将其排除在搜索空间之外。MobileNetV3 的最小化变种也放弃了这些操作的使用(例如 squeeze-and-excitation、swish 和 5x5 卷积),这样可以使模型更容易地移植到其他一些硬件加速器上,例如 DSP 和 GPU 。
神经网络架构搜索基于同时优化模型精确度和 Edge TPU 延时的动机,其生成的 MobileNetEdgeTPU 模型在固定某个精度时达到了更低的延时(或者在固定的延时条件下达到了更高的精确度,这是和之前像 MobileNetV2 和最小化的 MobileNetV3 模型相比的)。和 EfficientNet-EdgeTPU 模型(在 Coral 中为 Edge TPU 优化过的模型)相比,这些模型在 Pixel 4 上运行时的延时低得多,尽管代价是在精度上有点损失。
尽管减少模型的能耗并不是搜索目标的一部分,MobileNetEdgeTPU 模型的低延时还是帮助减少了 Edge TPU 的平均能耗。MobileNetEdgeTPU 模型在同样精确度情况下,只需要消耗最小化的 MobileNetV3 模型一半不到的能量。
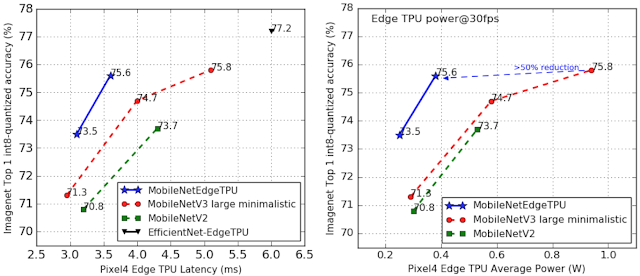
左侧:Pixel4 Edge TPU 上运行 MobileNetEdgeTPU 网络和其他移动端图像分类网络的精度对比情况,运行任务为 ImageNet 分类任务。MobileNetEdgeTPU 相比于其他模型实现了更高的精度和更低的延时。右侧:在每秒运行 30 帧(FPS)的情况下,不同分类模型在 Edge TPU 上的平均能耗(单位:瓦特)。
使用 MobileNetEdgeTPU 做物体检测
MobileNetEdgeTPU 分类模型还可以作为物体检测任务的高效特征提取器。和基于 MobileNetV2 的物体检测模型相比,MobileNetEdgeTPU 模型在模型质量方面有了重大改进(用 mean average precisin 指标来衡量,即 mAP),这是在 Edge TPU 上运行了足够多的 COCO 14 minival 数据集的结果。MobileNetEdgeTPU 检测模型延时为 6.6ms,mAP 分数达到了 24.3,而基于 MobileNetV2 的检测模型 mAP 只有 22,每次推理延时为 6.8ms。
硬件感知模型的必要性
以上结果凸显了 MobileNetEdgeTPU 模型在能耗、性能和质量方面带来的好处,值得注意的是,这些模型通过在 Edge TPU 加速器上运行而得到了定制化,这才有了这些方面的改进。MobileNetEdgeTPU 如果直接跑在移动端 CPU 上,其性能不如移动端 CPU 特意调过后的模型版本(如 MobileNetV3)。MobileNetEdgeTPU 模型执行的操作数量远超之前的模型版本,所以,它们在移动端 CPU 上运行的更慢也就不足为怪了,其在模型算力需求和运行时间之间展现出了更多的线性关系。
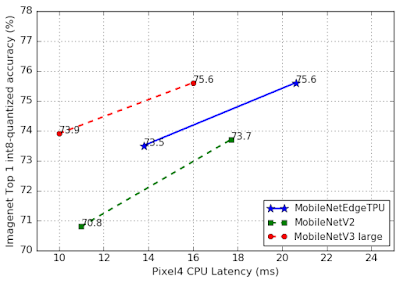
在使用移动端 CPU 时,MobileNetV3 仍然是部署到目标机器上性能表现最好的网络。
写给研究人员和开发人员
MobileNetV3 和 MobileNetEdgeTPU 代码,以及 ImageNet 分类任务对应的浮点和量化模型,可以在 MobileNet 的 github 页面下载:
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
MobileNetV3 和 MobileNetEdgeTPU 物体检测模型的开源实现可以在 Tensorflow 物体检测 API 页面获取:
https://github.com/tensorflow/models/tree/master/research/object_detection
MobileNetV3 语义分割的开源实现可以在 Tensorflow 代码库中的 DeepLab 获取:
https://github.com/tensorflow/models/tree/master/research/deeplab
致谢
这个工作是谷歌多个团队合作的成果。我们要感谢以下人员:Berkin Akin, Okan Arikan, Gabriel Bender, Bo Chen, Liang-Chieh Chen, Grace Chu, Eddy Hsu, John Joseph, Pieter-jan Kindermans, Quoc Le, Owen Lin, Hanxiao Liu, Yun Long, Ravi Narayanaswami, Ruoming Pang, Mark Sandler, Mingxing Tan, Vijay Vasudevan, Weijun Wang, Dong Hyuk Woo, Dmitry Kalenichenko, Yunyang Xiong, Yukun Zhu and support from Hartwig Adam, Blaise Agüera y Arcas, Chidu Krishnan 和 Steve Molloy。
原文链接:
https://ai.googleblog.com/2019/11/introducing-next-generation-on-device.html


