前言
敦煌系统 是我们政采云前端团队自研的项目开发全流程管理系统,目标是将项目开发的各流程全部管理起来。从项目创建,代码初始,到代码的本地开发,提测交付,测后发布,版本回滚,数据统计等。本文便是该系统中远程项目创建及数据统计部分的实现原理。后续陆续会有敦煌系统其余部分技术文章发布。欢迎大家先关注微信公众号 “政采云前端团队”,或者掘金上关注 “政采云前端团队”,以便第一时间获取最新信息。
简介
本文主要介绍如何通过 GitLab Open API 进行项目创建、初始化代码及团队代码量统计。前端工程化建设过程中,需要通过 Node 服务端进行 Git 仓库创建、项目初始化和代码量统计。经过一段时间开发探索,初步实现了需求。这里做个记录总结。
一、需求
创建仓库并进行代码初始化
目的:统一项目新建入口、项目开发模板,项目开发流程。节省新成员上手成本。
具体功能:团队成员可以通过输入项目名、GitLab 组、项目模板等字段直接创建 GitLab 仓库,并根据选择的模板及名称等信息在已创建的 GitLab 仓库里进行项目初始化。
代码量统计
目的
量化团队代码质量,统计团队工作量,监测业务吞吐量变化等。
在团队中推行 Commit 提交规范。
具体功能
获取团队成员的 Git Commit 信息,并存入数据库,以 Commit 信息数据为基础做数据统计分析。
提交信息不以 fix、feat、style、refactor 等开头的 Commit 可绘制饼图进行统计对比。以此推动 Commit 提交规范的施行。
单个 Commit 行数超出一定数量则在统计图中做出提示。
二、创建项目
看过 GitLab Open API 文档的人很容易就能找到创建接口,不过在创建之外我们还需要导入项目模板,修改相应的项目名称,描述,作者等信息。这涉及到多个接口的组合调用。
1、API 前缀 https://GitLabHost/api/v4 ,所有 GitLab Open API 都以此为前缀,举个创建项目接口的例子:https://GitLabHost/api/v4/projects 。
2、每个请求都需要带上创建者的 Private Token 作为参数。且要求该创建者有对应的权限。我这里使用了统一的用户 Front 作为创建人。这样一来创建项目就不需要获取每个用户的 Private Token 了。这样做还有个好处:统计代码量时,这部分复制代码的代码量会被算在 Front 这个虚拟用户上,减少统计误差。
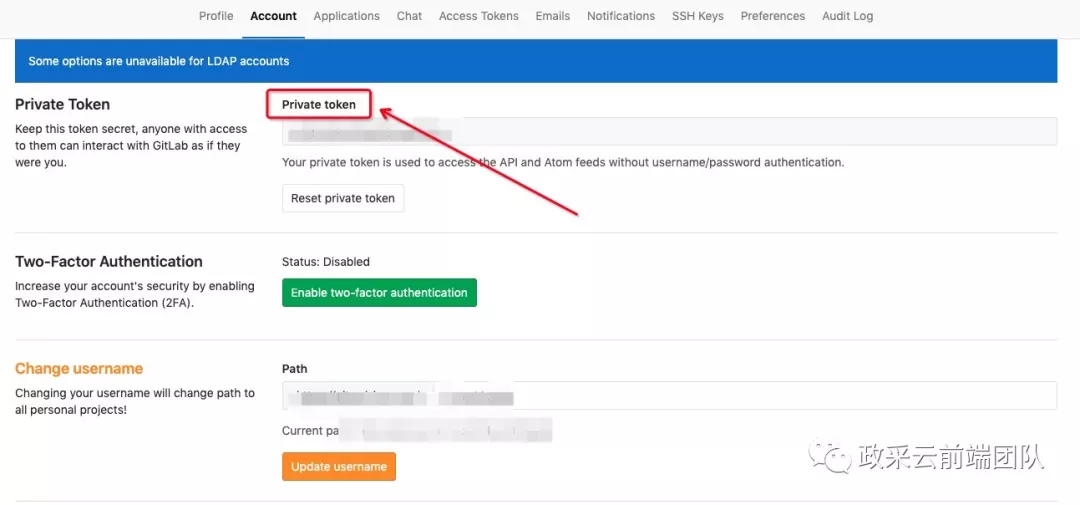 img
img
创建项目
POST /projects (此处只列中关键参数,更多参数请查看 GitLab 文档)
参数:
name: 项目名(不传 path 参数的话必填)
path: 项目路径(不传 name 参数的话必填)
namespace_id: 创建项目所在 Git 组的 id
description: 项目描述
import_url: 初始化项目的代码路径,格式:https://user:password@host/path.git
通过调用以上接口就可以在目标 Git 组中创建出一个带有初始化模板的项目了。
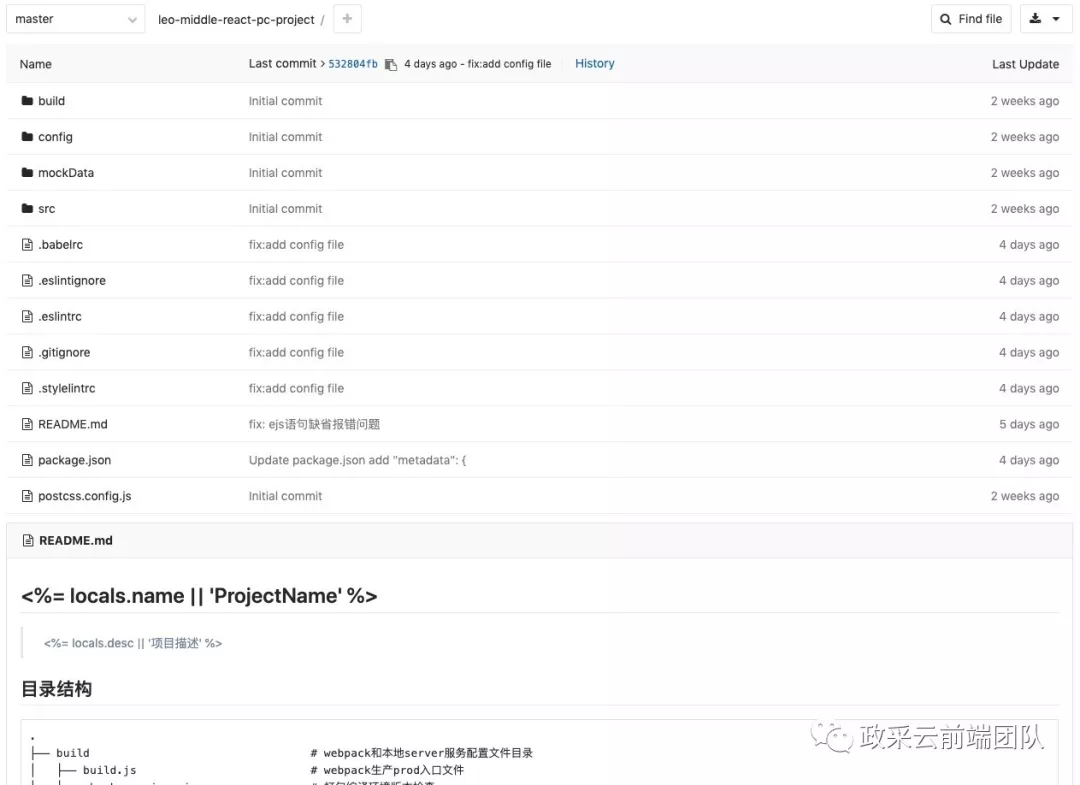 img
img
创建项目需要注意的是:
Front 要拥有目标 Git 组的 Master 权限才可以创建。这里就要求提前把 Front 加入到目标组中并赋予 Master 权限。以 front-test 组为例:
 img
img
当前用户也需要做权限判断,这里需要开发者在创建之前调用
GET /groups/:id/members接口获取组别用户并对比当前人是否有权限创建了。比如:
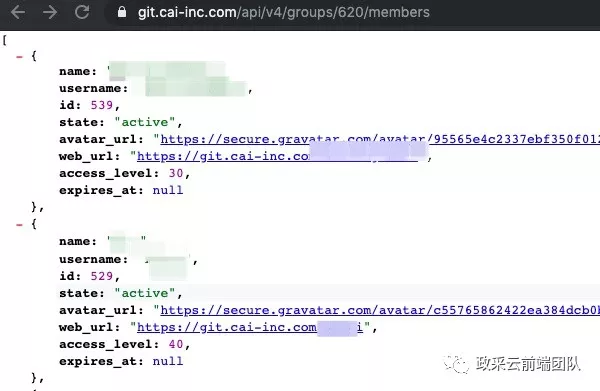 img
img
access_level 就是权限值,分别对应为
10 => Guest 权限
20 => Reporter 权限
30 => Developer 权限
40 => Master 权限
50 => Owner 权限
初始化项目信息
创建完项目之后要初始化项目信息,细心的同学可以发现上面创建好的项目中的 README.md 里面的 name ,desc 还没有被替换掉,接下来我们就要替换包括 README.md 和 Package.json 两个文件中的一些关键信息了。
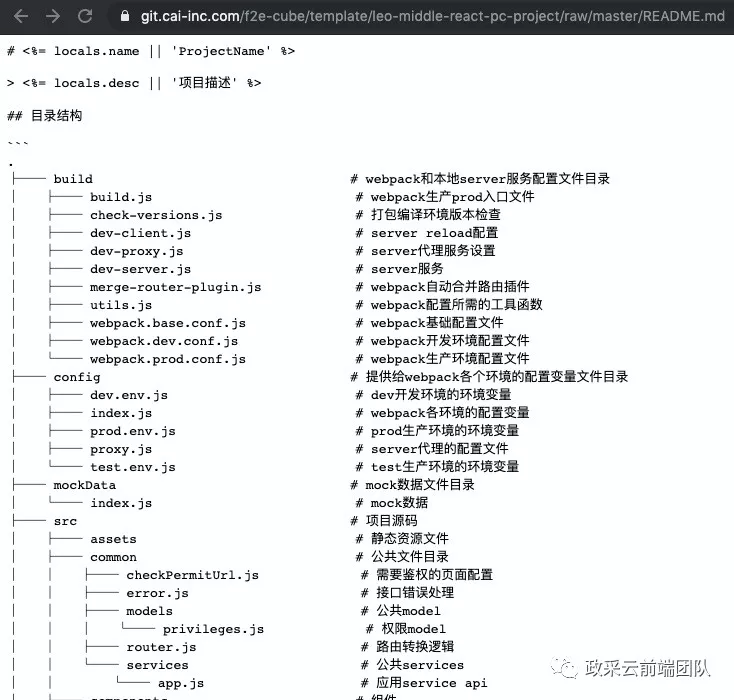
读取对应的文件,这里直接在浏览器中访问对应文件然后把路径中的 blob 改成 raw 就可以直接读取到对应的文件信息了。
举个例子:https://GitLabHost/f2e-cube/template/leo-middle-react-pc-project/blob/master/README.md 这个链接可以直接访问到项目文件页面,但得到却不是单纯的文件信息。
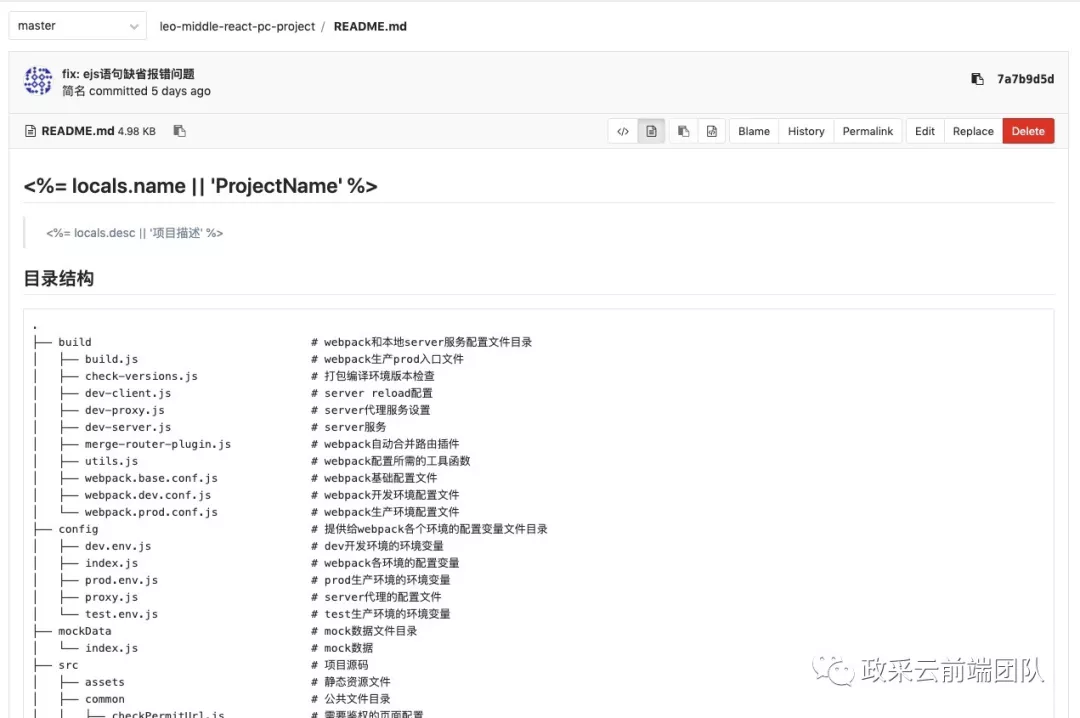 img
img
把 blob 改成 raw 即直接访问
https://GitLabHost/f2e-cube/template/leo-front-vue-pc-component/raw/master/README.md就可以直接获取到文件内容了。
 img
img
读取到文件信息之后,使用 Node 模板引擎把对应的数据注入到获取的文件信息中就可以了。这里服务端使用的是 EggJs 框架。模板引擎选用 Ejs 。
关键代码:
const result = await this.ctx.renderString(readMeStr, { author: userInfo.userName, name: gitProjectInfo.name, description: project.desc, ...others, });复制代码
将渲染完成的字符串提交到已经创建的项目中。使用到创建 Commit 接口。
POST /projects/:id/repository/commits (此处只列中关键参数,更多参数请查看 GitLab 文档)参数:id: 项目 id (刚刚创建好项目时有返回项目信息,里面包含项目 id)branch: 分支(这里一般是 Master )commit_message: commit 信息 actions: [] 修改项 action: 变更类型 create, delete, move, update (这里是 update) file_path: 变更文件的路径 content: 变更后的内容即上面代码中的 result
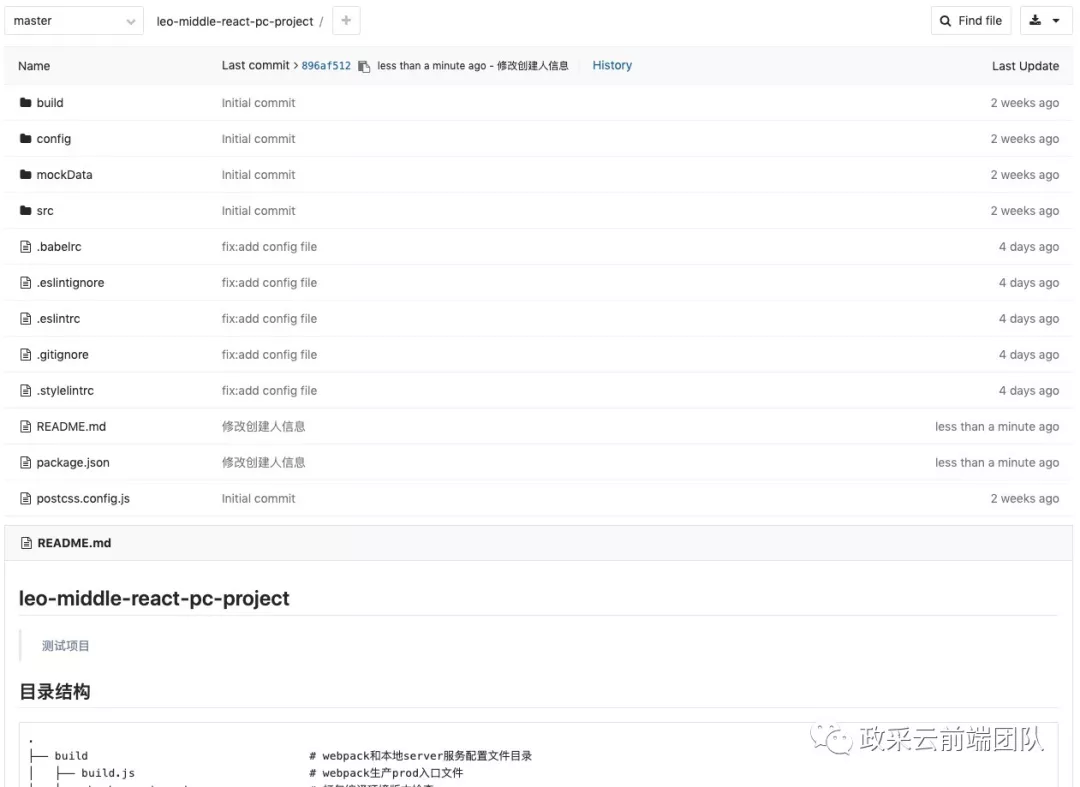
至此,项目创建并初始化完成!
 img
img
可以看到 name 和 desc 已经被替换成相应的项目名及中文描述了。
三、代码量统计
代码量统计,在百度,谷歌搜索一下能搜出来一大把,但是基本上都是代码拉到本地后,执行命令获取项目的代码量或者项目代码的贡献者的代码量。比较普遍的方案是给项目加 Git Hook 。在项目提交之前调用请求把当前提交的代码量传给后端进行储存统计。这样做的弊端有
需要所有的项目都加上 Git Hook 。对于几十上百个历史项目的团队而言是个不小问题。
历史数据统计不到。
GitLab API 中有个实体叫做 Event ,用户每个操作都会有对应的 Event 产生并储存。我们这里便是通过 Event 进行代码量统计。
基本信息
API 前缀
https://GitLabHost/api/v4每个请求都需要带上查询用户的 Private Token 作为参数。且要求该查询用户有对应的权限。我这里使用了统一的用户 Front 做为查询用户。所有被统计项目中都需要加入 Front ,并赋予 Developer 及以上权限。(可以直接通过组赋权)
获取所有需要统计代码量的用户的用户名
首先通过钉钉接口获取团队所有用户的用户名(团队钉钉用户名和 Git 用户名相同)。这一步对于不是太大的团队可以通过手动获取。
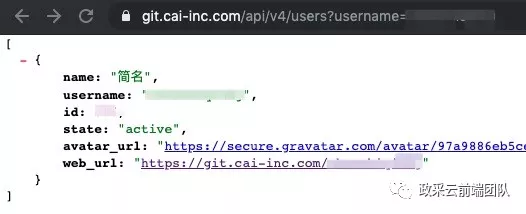
获取对应用户的 Git Id (如果团队人员少,可手动收集)
通过 GET /users?username=:username 接口获取用户对应的 Git User 的 Id 。
 img
img
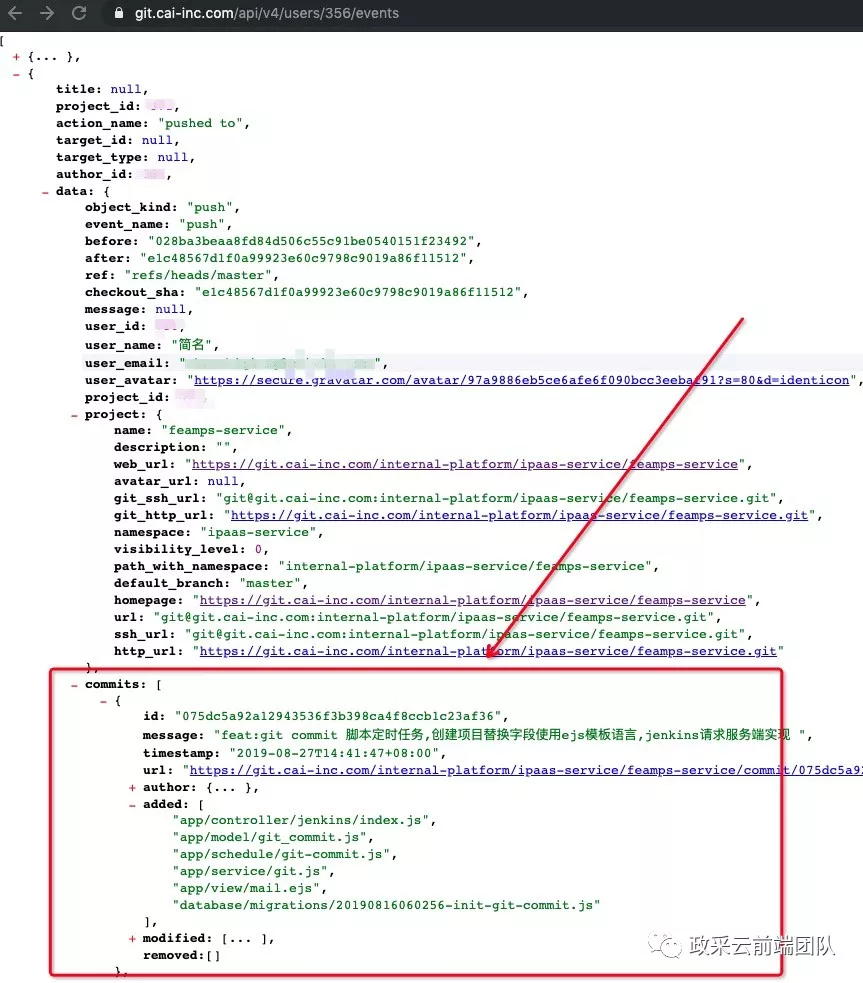
查询用户的 Event
获取到所有用户 Id 之后就可以调用 GET /users/:id/events 这个接口查询到当前用户的所有 Event 。这里会包括有 Push 的 Event 。Event 中会有对应 Commit 信息和项目信息。不过这里的 Commit 信息不全,不包含添加多少行代码,删除多少行代码,总共多少行代码的信息。
 img
img
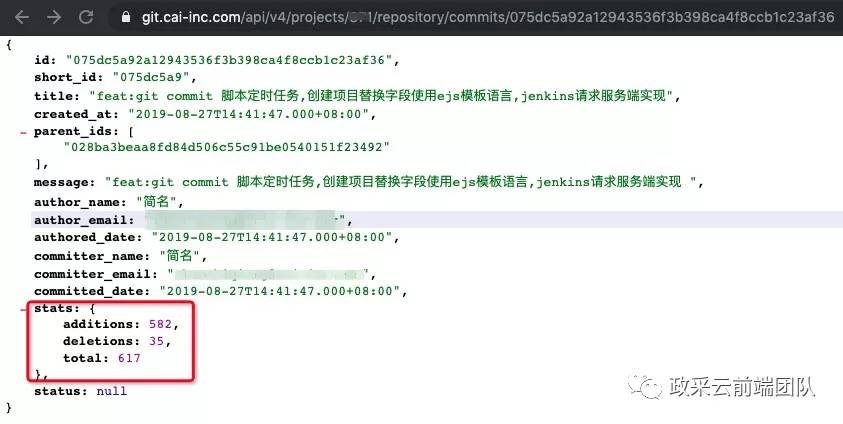
获取 Commit 的详细信息
通过上一步获取的 Commit 信息中的 Id 和项目 Id 再查询 Commit 的详细信息: GET /projects/:id/repository/commits/:sha 。这里这里就可以获取到 Commit 的 Stats 信息了。里面包含 additions, deletions, total 信息。
 img
img
存数据库并设定定时任务
将获取到的数据存入数据库就可以做代码量统计了。然后设置定时任务,每周跑一次或两次进行代码量统计。
需要注意的有
有些操作或导致 Commit 重复,所以对于同一个人的 Commit 需要做去重。
GitLab Events 只会存近一年的数据。所以运行当天也只能统计近一年的代码。
一定要按人进行 Push 时间划分,这样第一次运行之后,后面就可以只取上次取的最后一次 Push 的时间之后的 Commit 了。请求数可以减少很多。
执行过代码之后发现了一些问题,比如:团队成员误操作将 node_modules 文件夹上传等。这造成了统计代码行数过多,解决办法是过滤掉大于 10000 行(这个可以自由指定)的 commit 。
问题
因为接口限制,请求数太多了,所以第一次跑任务会有点慢,大概需要我们团队 40 多人大概需要跑二、三十分钟。
后续
最新版本的 GitLab Open API 使用了 GraphQL 技术。可以解决以上问题。
后记
其实最开始的文章,我们没有表述清楚,是我们写稿和审稿没注意到“代码量审核”会对一些看官带来困扰。大家所处公司不一样,可能确实会有部分公司,会以代码量的多少来简单粗暴的计算员工的 KPI,这点我们同样觉得是不妥的。文中提及的代码及代码量的目的,在于便于接入团队的代码合规检测(如兼容性 api 检测、lint 检测)服务,也在于便于从数据维度进行量化,验证架构的升级和基础设施的完善,对同学工作量的降低,可以有数据指标进行说明。我们希望基于技术、架构的升级,基础设施和工具链路的完善,帮我们做到接近 less code 的目标,帮我们的同学变得更“懒”,能腾出更多时间去去关注和研究对业务的未来、个人的未来更有价值的事。也希望你能一起加入,帮我们更快接近、达到这一目标。
头图:Unsplash
作者:简明
原文:https://mp.weixin.qq.com/s/oZrc0PqFTHBZejOUV1CCQg


