
作者:张汉东 ,《Rust 编程之道》作者,独立企业咨询顾问,开源爱好者。喜欢读书、写作、分享,欢迎交流。原文链接:https://mp.weixin.qq.com/s/9rjeVgVzmrC0wWhV4wA9FA
文前
Rust 语言是一门通用系统级编程语言,无 GC 且能保证内存安全、并发安全和高性能而著称。自 2008 年开始由 Graydon Hoare 私人研发,2009 年得到 Mozilla 赞助,2010 年首次发布 0.1.0 版本,用于 Servo 引擎的研发,于 2015 年 5 月 15 号发布 1.0 版本。
自发布以来,截止到 2021 年的今天,经历六年的发展,Rust 得到稳步上升,已逐渐趋于成熟稳定。
至 2016 年开始,截止到 2021 年,Rust 连续五年成为 StackOverflow 语言榜上最受欢迎的语言。

2021 年 2 月 9 号,Rust 基金会宣布成立。华为、AWS、Google、微软、Mozilla、Facebook 等科技行业领军巨头加入 Rust 基金会,成为白金成员,以致力于在全球范围内推广和发展 Rust 语言。
那 Rust 语言到底有何魅力,能让广大开发者和巨头公司这么感兴趣呢?
本文打算从 Rust 语言自身特性 和 Rust 行业应用盘点两个方面的社区调研来尝试来解答这个问题。供想选择 Rust 的公司参考。
其实 Rust 生态还有很多内容,等待大家挖掘。本文内容还未覆盖完全 Rust 生态的方方面面。
注明: 本文中所罗列数据均来源互联网公开内容。
认识 Rust 语言
编程语言设计在两个看似不可调和的愿望之间长期存在着矛盾对立。
安全 ( safe )。 我们想要强类型系统来静态地排除大量错误。 我们要自动内存管理。我们想要数据封装, 这样我们就可以对私有变量执行不变的对象的表示形式,并确保它们将不会被不受信任的代码破坏。
控制 (control )。 至少对于 Web 浏览器,操作系统,或游戏引擎这样的
系统编程 (system programming)程序,约束它们性能或资源是一个重要的问题,我们想了解数据的字节级表示。 我们想要用底层语言 (low-level programming)的编程技术优化我们程序的时间和空间的使用。 我们希望在需要时使用裸机。
然而,按照传统的看法,鱼和熊掌不能兼得。 Java 之类的语言使我们极大的安全保证,但代价是牺牲对底层的控制。结果,对于许多系统编程应用程序,唯一现实的选择是使用一种像 C 或 C++ 提供细粒度的语言控制资源管理。 但是,获得这种控制需要很高的成本。例如,微软最近报告说,他们修复的 70% 安全漏洞都归因于内存安全违规行为 33,并且都是能被强类型系统排除的问题。同样,Mozilla 报告指出,绝大多数关键 他们在 Firefox 中发现的错误是内存有关的16 。
如果可以以某种方式两全其美: 安全系统编程的同时对底层有控制权,岂不美哉。因此,Rust 语言应运而生。
官方网如此介绍 Rust : 一门赋予每个人 构建可靠且高效软件能力的语言。
Rust 语言有三大优势值得大家关注:
高性能。Rust 速度惊人且内存利用率极高。由于没有运行时和垃圾回收,它能够胜任对性能要求特别高的服务,可以在嵌入式设备上运行,还能轻松和其他语言集成。
可靠性。Rust 丰富的类型系统和所有权模型保证了内存安全和线程安全,让您在编译期就能够消除各种各样的错误。
生产力。Rust 拥有出色的文档、友好的编译器和清晰的错误提示信息, 还集成了一流的工具——包管理器和构建工具, 智能地自动补全和类型检验的多编辑器支持, 以及自动格式化代码等等。
Rust 足够底层,如果有必要,它可以像 C 一样进行优化,以实现最高性能。
抽象层次越高,内存管理越方便,可用库越丰富,Rust 程序代码就越多,做的事情越多,但如果不进行控制,可能导致程序膨胀。
然而,Rust 程序的优化也很不错,有时候比 C 语言更好,C 语言适合在逐个字节逐个指针的级别上编写最小的代码,而 Rust 具有强大的功能,能够有效地将多个函数甚至整个库组合在一起。
但是,最大的潜力是可以无畏(fearless)地并行化大多数 Rust 代码,即使等价的 C 代码并行化的风险非常高。在这方面,Rust 语言是比 C 语言更为成熟的语言。
Rust 语言也支持高并发零成本的异步编程,Rust 语言应该是首个支持异步编程的系统级语言。
媲美 C / Cpp 的高性能
Rust vs C
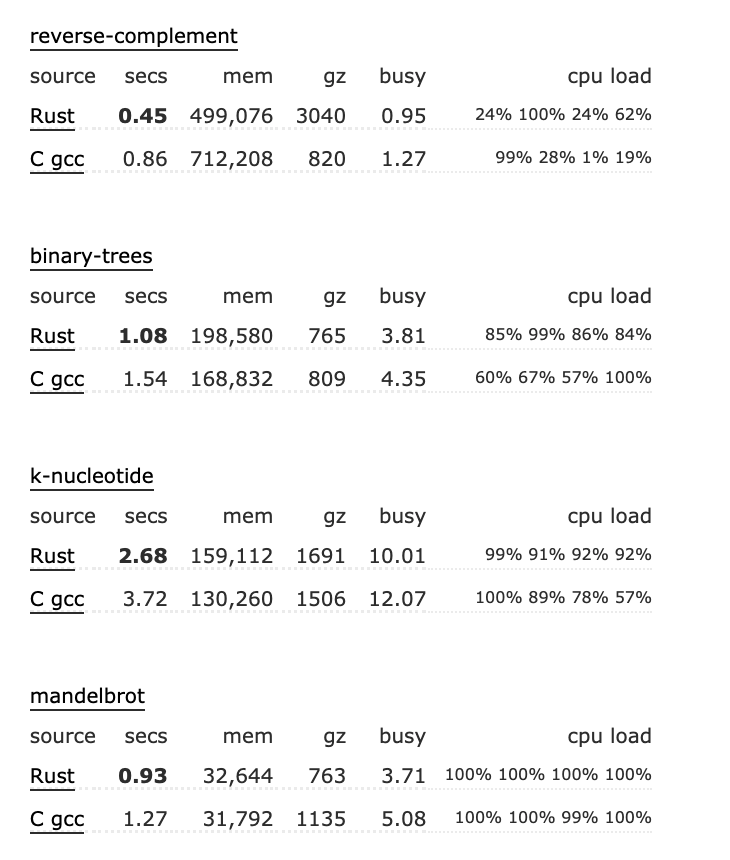
Rust vs Cpp
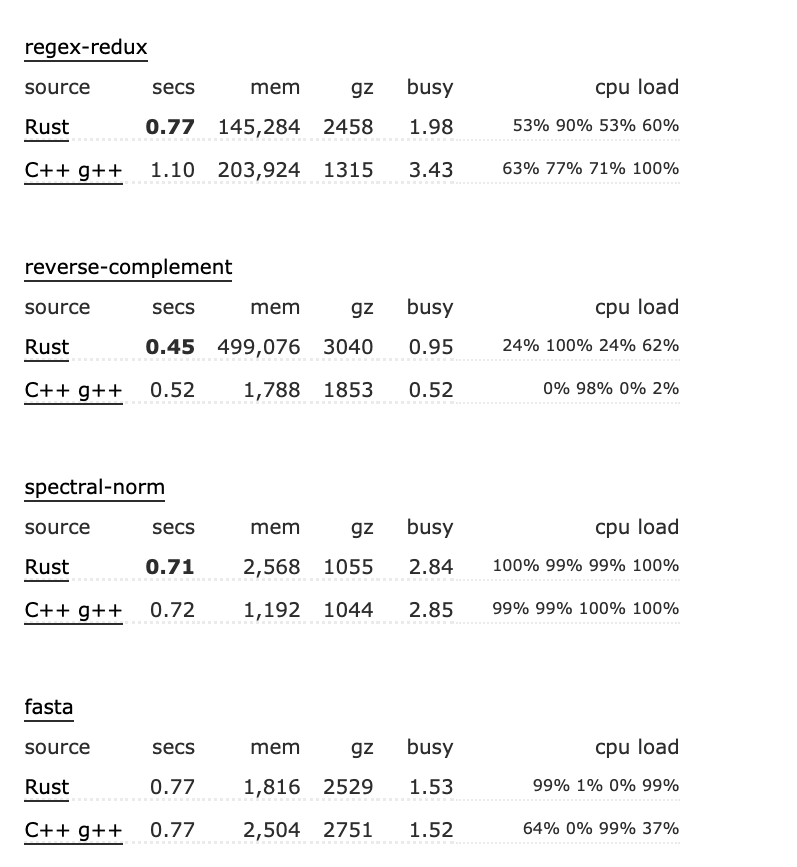
Rust vs Go
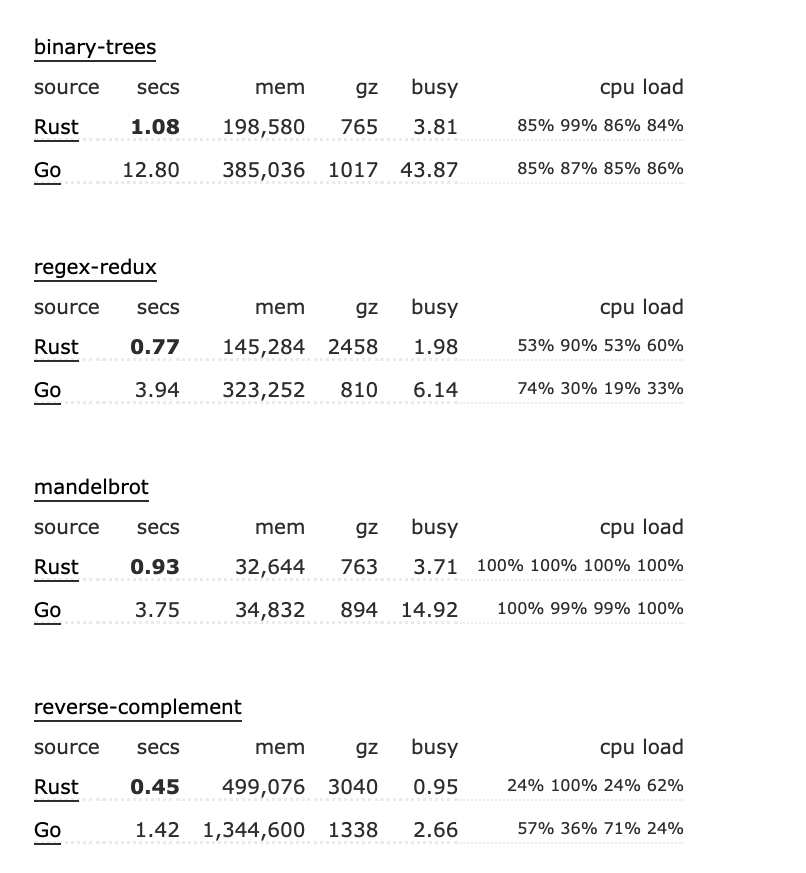
用 Rust 编写的程序的运行时速度和内存使用量应该和用 C 编写的程序差不多,但这两种语言的总体编程风格不同,很难去概括它们的性能。
总的来说:
抽象是一把双刃剑。Rust 语言抽象程度比 C 语言更高,抽象会隐藏一些不是那么优化的代码,这意味着,默认实现的 Rust 代码性能不是最好的。所以,你的 Rust 代码必须经过优化才能达到媲美 C 的性能。Unsafe Rust 就是高性能出口。
Rust 默认线程安全,消除数据竞争,让多线程并发编程更具实用价值。
Rust 在有些方面确实比 C 快。理论上,C 语言什么都可以做。 但在实践中,C 抽象能力比较低,不那么现代化,开发效率比较低。只要开发者有无限时间和精力,就可以让 C 语言在这些方面比 Rust 更快。
因为 C 语言足以代表高性能,下面就分别谈一下 C 和 Rust 的异同。如果你熟悉 C/Cpp,也可以根据此对比来评估 Cpp 和 Rust。
Rust 和 C 都是硬件直接抽象
Rust 和 C 都是直接对硬件的抽象,都可看作一种「可移植汇编程序」。
Rust 和 C 都能控制数据结构的内存布局、整数大小、栈与堆内存分配、指针间接寻址等,并且一般都能翻译成可理解的机器代码,编译器很少插入 "魔法"。
即便 Rust 比 C 有更高层次的结构,如迭代器、特质(trait)和智能指针,它们也被设计为可预测地优化为简单的机器代码(又称 "零成本抽象")。
Rust 的类型的内存布局很简单,例如,可增长的字符串String 和 Vec<T> 正好是{byte*, capacity, length}。Rust 没有任何像 Cpp 里的 移动 或 复制构造函数 这样的概念,所以对象的传递保证不会比传递指针或 memcpy 更复杂。
Rust 借用检查只是编译器对代码中引用的静态分析。生命周期(lifetime)信息早就在 中级中间语言(MIR) 生成前完全抽离了。
Rust 中不使用传统的异常处理,而是使用基于返回值的错误处理。但你也可以使用 恐慌(Panic)来处理像 Cpp 中那样的异常行为。它可以在编译时被禁用(panic = abort),但即便如此,Rust 也不喜欢 与 Cpp 异常 或 longjmp 混在一起。
同样的 LLVM 后端
Rust 与 LLVM 有很好的整合,所以它支持链接时间优化,包括 ThinLTO,甚至是跨越 C/C++/Rust 语言边界的内联。也有按配置优化(Profile-guided Optimization,PGO)的支持。尽管 rustc 比 clang 生成的 LLVM IR 更加冗长,但优化器仍然能够很好地处理它。
C 语言用 GCC 编译比用 LLVM 更快,现在 Rust 社区也有人在开发 GCC 的 Rust 前端。
理论上,因为 Rust 有比 C 更严格的不可变和别名规则,应该比 C 语言有更好的性能优化,但实际上并没有起到这样的效果。目前在 LLVM 中,超越 C 语言的优化是一项正在进行的工作,所以 Rust 仍然没有达到其全部潜力。
都允许手工优化,但有一些小例外
Rust 的代码足够底层和可预测,可以通过手工调整它的优化到什么样的汇编代码。
Rust 支持 SIMD ,对内联和调用约定有很好的控制。
Rust 和 C 语言足够相似,C 语言的一些分析工具通常可以用于 Rust 。
总的来说,如果性能绝对关键,并且需要手工优化压榨最后一点性能,那么优化 Rus t 与 优化 C 语言并没有什么不同。
但是在一些比较底层的特性,Rust 没有特别好的替代方法。
goto。Rust 中没有提供goto,不过你可以使用循环的 break 标签来代替。C 语言中一般使用 goto 来清理内存,但是 Rust 因为有确定性析构功能,所以不需要 goto。然而有一个 非标准的 goto 扩展,对性能优化比较有用。栈内存分配
alloca和C99可变长度数组,可以节省内存空间,减少内存分配次数。但这些即使在 C 语言中也是有争议的,所以 Rust 远离了它们。
Rust 相比 C 语言的一些开销
如果没有经过手工优化,Rust 因为其抽象表达也会有一些开销。
Rust 缺乏隐式类型转换和只用 usize 的索引,这导致开发者只能使用这种类型,哪怕只需要更小的数据类型。64 位平台上用 usize 做索引更容易优化,而不需要担心未定义行为,但多余的 bit 位可能会给寄存器和内存带来更大的压力。而在 C 中,你可以选择 32 位类型。
Rust 中的字符串,总是会携带指针和长度。但是很多 C 代码中的函数只接收指针而不管大小。
像
for i in 0...len {arr[i]}这样的迭代,性能取决于 LLVM 优化器能否证明长度匹配。有时候,它不能,并且边界检查也会抑制自动矢量化。C 语言比较自由,对于内存有很多“聪明”的使用技巧,但在 Rust 里就没这么自由了。但 Rust 仍然给了内存分配很多控制权,并且可以做一些基本的事情,比如内存池、将多个分配合并为一个、预分配空间等等。
在不熟悉 Rust 借用检查的情况下,可能会用 Clone 来逃避使用引用。
Rust 的标准库中 I/O 是不带缓存的,所以需要使用 BufWriter 来包装。这就是为什么有些人说 Rust 写的代码还不如 Python 快的原因,因为 99% 的时间都用在 I/O 上了。
可执行文件大小
每个操作系统都有一些内置的标准 C 库,其中有大约 30MB 的代码。C 语言的执行文件,可以“免费”使用这些库。
一个小的 "Hello World " 级 C 可执行文件实际上不能打印任何东西,它只调用操作系统提供的 printf。
而 Rust 则不可以,Rust 可执行文件会捆绑自己的标准库(300KB 或更多)。幸运的是,这只是一次性的开销,可以减少。
对于嵌入式开发,可以关闭标准库,使用 "no-std",Rust 将生成 "裸 "代码。
在每个函数的基础上,Rust 代码的大小与 C 差不多,但有一个 "泛型膨胀 "的问题。泛型函数为它们所使用的每一种类型都有优化的版本,所以有可能出现同一个函数有 8 个版本的情况,cargo-bloat 库有助于发现这些问题。
在 Rust 中使用依赖关系是非常容易的。与 JS/npm 类似,现在推荐使用小型且单用途的包,但它们确实在不断增加。cargo-tree 命令对于删减它们非常有用。
Rust 略胜 C 的一些地方
为了隐藏实现细节,C 库经常返回不透明的数据结构指针,并确保结构的每个实例只有一个副本。它会消耗堆分配和指针间接寻址的成本。Rust 内置的隐私、单一所有权规则和编码惯例允许库暴露其对象,而不需要间接性,这样,调用者可以决定将其放入堆(heap)上还是栈(stack)中。可以主动或彻底地优化栈上的对象。
缺省情况下,Rust 可以将来自标准库、依赖项和其他编译单元的函数内联。
Rust 会对结构体字段进行重排,以优化内存布局。
字符串携带大小信息,使得长度检查速度很快。并允许就地生成子串。
与 C++ 模板类似,Rust 中泛型函数会单态化,生成不同类型的副本,因此像 sort 这样的函数和 HashMap 这样的容器总是针对相应的类型进行优化。对于 C 语言,则必须在修改宏或者处理
void*和运行时变量大小的效率较低的函数之间做出选择。Rust 的迭代器可以组合成链状,作为一个单元一起被优化。因此,你可以调用
it.buy().use().break().change().mail().upgrade(),而不是对同一个缓存区多次写入的一系列调用。同样,通过 Read 和 Write 接口,接收一些未缓存的流数据,在流中执行 CRC 校验,然后将其转码、压缩,再写入网络中,所有这些都可以在一次调用中完成。虽然 C 语言中应该也可以做到,但它没有泛型和特质(trait),将很难做到。
Rust 标准库中内置高质量的容器和优化过的数据结构,比 C 使用起来更方便。
Rust 的 serde 是世界上最快的 JSON 解析器之一,使用体验非常棒。
Rust 比 C 明显优越的地方
主要是两点:
Rust 消除数据竞争,天生线程安全,解放多线程生产力,是 Rust 明显比 C / Cpp 等语言优越的地方。
Rust 语言支持异步高并发编程。
Rust 支持 安全的编译期计算。
线程安全
即使是在第三方库中,Rust 也会强制实现所有代码和数据的线程安全,哪怕那些代码的作者没有注意线程安全。一切都遵循一个特定的线程安全保证,或者不允许跨线程使用。当你编写的代码不符合线程安全时,编译器会准确地指出不安全之处。
Rust 生态中已经有了很多库,如数据并行、线程池、队列、任务、无锁数据结构等。有了这类组件的帮助,再加上类型系统强大的安全网,完全可以很轻松地实现并发/并行化 Rust 程序。有些情况下,用 par_iter 代替 iter 是可以的,只要能够进行编译,就可以正常工作!这并不总是线性加速( 阿姆达尔定律(Amdahl's law)很残酷),但往往是相对较少的工作就能加速 2~3 倍。
延伸:阿姆达尔定律,一个计算机科学界的经验法则,因 Gene Amdahl 而得名。它代表了处理器并行计算之后效率提升的能力。
在记录线程安全方面,Rust 和 C 有一个有趣的不同。
Rust 有一个术语表用于描述线程安全的特定方面,如 Send 和 Sync、guards 和 cell。
对于 C 库,没有这样的说法:“可以在一个线程上分配它,在另一个线程上释放它,但不能同时从两个线程中使用它”。
根据数据类型,Rust 描述了线程安全性,它可以泛化到所有使用它们的函数。
对于 C 语言来说,线程安全只涉及单个函数和配置标志。
Rust 的保证通常是在编译时提供的,至少是无条件的。
对于 C 语言,常见的是“仅当 turboblub 选项设置为 7 时,这才是线程安全的” (这句话并不是真的让你去设置 turboblub 选项,因为本来就没有这个选项,所以 C 语言不会保证你线程安全 )。
异步并发
Rust 语言支持 async/await异步编程模型。
该编程模型,基于一个叫做 Future 的概念,,在 JavaScript 中也叫做 Promise。Future 表示一个尚未得出的值,你可以在它被解决(resolved)以得出那个值之前对它进行各种操作。在许多语言中,对 Future 所做的工作并不多,这种实现支持很多特性比如组合器(Combinator),尤其是能在此基础上实现更符合人体工程学的 async/await 语法。
Future 可以表示各种各样的东西,尤其适用于表示异步 I/O :当你发起一次网络请求时,你将立即获得一个 Future 对象,而一旦网络请求完成,它将返回任何响应可能包含的值;你也可以表示诸如“超时”之类的东西,“超时”其实就是一个在过了特定时间后被解决的 Future ;甚至不属于 I/O 的工作或者需要放到某个线程池中运行的 CPU 密集型的工作,也可以通过一个 Future 来表示,这个 Future 将会在线程池完成工作后被解决。
Future 存在的问题 是它在大多数语言中的表示方式是这种基于回调的方法,使用这种方式时,你可以指定在 Future 被解决之后运行什么回调函数。也就是说, Future 负责弄清楚什么时候被解决,无论你的回调是什么,它都会运行;而所有的不便也都建立在此模型上,它非常难用,因为已经有很多开发者进行了大量的尝试,发现他们不得不写很多分配性的代码以及使用动态派发;实际上,你尝试调度的每个回调都必须获得自己独立的存储空间,例如 crate 对象、堆内存分配,这些分配以及动态派发无处不在。这种方法没有满足零成本抽象的第二个原则,如果你要使用它,它将比你自己写要慢很多,那你为什么还要用它。
Rust 中的方案有所不同。不是由 Future 来调度回调函数,而是由一个被称为执行器(executor)的组件去轮询 Future。而 Future 可能返回“尚未准备就绪(Pending)”,也可能被解决就返回“已就绪(Ready)”。该模型有很多优点。其中一个优点是,你可以非常容易地取消 Future ,因为取消 Future 只需要停止持有 Future。而如果采用基于回调的方法,要通过调度来取消并使其停止就没这么容易了。
同时它还能够使我们在程序的不同部分之间建立真正清晰的抽象边界,大多数其他 Future 库都带有事件循环(event loop),这也是调度 你的Future 执行 I/O 的方法,但实际上你对此没有任何控制权。
而在 Rust 中,各组件之间的边界非常整洁,执行器(executor)负责调度你的 Future ,反应器(reactor)处理所有的 I/O ,然后是你的实际代码。因此最终用户可以自行决定使用什么执行器,使用他们想使用的反应器,从而获得更强的控制力,这在系统编程语言中真的很重要。
而此模型最重要的真正优势在于,它使我们能够以一种真正零成本的完美方式实现这种状态机式的 Future 。也就是当你编写的 Future 代码被编译成实际的本地(native)代码时,它就像一个状态机;在该状态机中,每次 I/O 的暂停点都有一个变体(variant),而每个变体都保存了恢复执行所需的状态。
而这种 Future 抽象的真正有用之处在于,我们可以在其之上构建其他 API 。可以通过将这些组合器方法应用于 Future 来构建状态机,它们的工作方式类似于迭代器(Iterator)的适配器(如 filter、map)。但是这种方式是有一些缺点的,尤其是诸如嵌套回调之类,可读性非常差。所以才需要实现 async / await异步语法。
目前 Rust 生态中,已经有了成熟的 tokio 运行时生态,支持 epoll 等异步 I/O。如果你想用 io_uring ,也可以使用 Glommio ,或者等待 tokio 对 io_uring 的支持。甚至,你可以使用 smol 运行时提供的 async_executor 和 async-io 来构建你自己的运行时。
编译期计算
Rust 可以支持类似于 Cpp 那样的 编译期常量求值。这一点是明显比 C 优越的。
虽然目前功能还不如 Cpp 那样强大,但还在不断的维护中。
为什么 Rust 中支持 编译期计算这么谨慎呢?因为 Rust 编译期求值是必须要保证安全的,所以有很多考虑。Rust 编译期求值不像 Cpp 那样自由且容易滥用。
可靠性
2020 年 6 月份,来自 3 所大学的 5 位学者在 ACM SIGPLAN 国际会议(PLDI'20)上发表了一篇研究成果,针对近几年使用 Rust 语言的开源项目中的安全缺陷进行了全面的调查。这项研究调查了 5 个使用 Rust 语言开发的软件系统,5 个被广泛使用的 Rust 库,以及两个漏洞数据库。调查总共涉及了 850 处 unsafe 代码使用、70 个内存安全缺陷、100 个线程安全缺陷。
在调查中,研究员不光查看了所有漏洞数据库中报告的缺陷和软件公开报告的缺陷,还查看了所有开源软件代码仓库中的提交记录。通过人工的分析,他们界定出提交所修复的 BUG 类型,并将其归类到相应的内存安全/线程安全问题中。所有被调查过的问题都被整理到了公开的 Git 仓库中:https://github.com/system-pclub/rust-study
调查结果说明:
Rust 语言的 safe 代码对于空间和时间内存安全问题的检查非常有效,所有稳定版本中出现的内存安全问题都和 unsafe 代码有关。
虽然内存安全问题都和 unsafe 代码有关,但大量的问题同时也和 safe 代码有关。有些问题甚至源于 safe 代码的编码错误,而不是 unsafe 代码。
线程安全问题,无论阻塞还是非阻塞,都可以在 safe 代码中发生,即使代码完全符合 Rust 语言的规则。
大量问题的产生是由于编码人员没有正确理解 Rust 语言的生命周期规则导致的。
有必要针对 Rust 语言中的典型问题,建立新的缺陷检测工具。
那么这份调查报告背后 Rust 的安全性是如何保证的呢?Unsafe Rust 又是为什么 Unsafe 呢?
所有权: Rust 语言内存安全机制
Rust 的设计深深地吸取了关于安全系统编程的学术研究的精髓。特别是,与其他主流语言相比,Rust 设计的最大特色在于采用了所有权类型系统(在学术文献中通常称为仿射或子结构类型系统36)。
所有权机制,就是 Rust 语言借助类型系统,承载其“内存安全”的思想,表达出来的安全编程语义和模型。
所有权机制要解决的内存不安全问题包括:
引用空指针。
使用未初始化内存。
释放后使用,也就是使用悬垂指针。
缓冲区溢出,比如数组越界。
非法释放已经释放过的指针或未分配的指针,也就是重复释放。
注意,内存泄露不属于内存安全问题范畴,所以 Rust 也不解决内存泄露问题。
为了保证内存安全,Rust 语言建立了严格的安全内存管理模型:
所有权系统。每个被分配的内存都有一个独占其所有权的指针。只有当该指针被销毁时,其对应的内存才能随之被释放。
借用和生命周期。每个变量都有其生命周期,一旦超出生命周期,变量就会被自动释放。如果是借用,则可以通过标记生命周期参数供编译器检查的方式,防止出现悬垂指针,也就是释放后使用的情况。
其中所有权系统还包括了从现代 C++ 那里借鉴的 RAII 机制,这是 Rust 无 GC 但是可以安全管理内存的基石。
建立了安全内存管理模型之后,再用类型系统表达出来即可。Rust 从 Haskell 的类型系统那里借鉴了以下特性:
没有空指针
默认不可变
表达式
高阶函数
代数数据类型
模式匹配
泛型
trait 和关联类型
本地类型推导
为了实现内存安全,Rust 还具备以下独有的特性:
仿射类型(Affine Type),该类型用来表达 Rust 所有权中的 Move 语义。
借用、生命周期。
借助类型系统的强大,Rust 编译器可以在编译期对类型进行检查,看其是否满足安全内存模型,在编译期就能发现内存不安全问题,有效地阻止未定义行为的发生。
内存安全的 Bug 和并发安全的 Bug 产生的内在原因是相同的,都是因为内存的不正当访问而造成的。同样,利用装载了所有权的强大类型系统,Rust 还解决了并发安全的问题。Rust 编译器会通过静态检查分析,在编译期就检查出多线程并发代码中所有的数据竞争问题。
Unsafe Rust :划分安全边界
**为了和现有的生态系统良好地集成,**Rust 支持非常方便且零成本的 FFI 机制,兼容 C-ABI,并且从语言架构层面上将 Rust 语言分成 Safe Rust 和 Unsafe Rust 两部分。
其中 Unsafe Rust 专门和外部系统打交道,比如操作系统内核。之所以这样划分,是因为 Rust 编译器的检查和跟踪是有能力范围的,它不可能检查到外部其他语言接口的安全状态,所以只能靠开发者自己来保证安全。
Rust 的最终目标并不是完全消除那些危险点,因为在某种程度上,我们需要能够访问内存和其他资源。实际上,Rust 的目标是将所有的 unsafe 元素抽象出来。在考虑安全性时,你需要考虑“攻击面”,或者我们可以与程序的哪些部分进行交互。像解析器这样的东西是一个很大的攻击面,因为:
它们通常可以被攻击者访问;
攻击者提供的数据可以直接影响解析通常需要的复杂逻辑。
你可以进一步分解,将传统的攻击面分解成“攻击面”(可以直接影响程序代码的部分)和“安全层”,这部分代码是攻击面依赖的代码,但是无法访问,而且可能存在潜在的 Bug。在 C 语言中,它们是一样的:C 语言中的数组根本不是抽象的,所以如果你读取了可变数量的项,就需要确保所有的不变量都保持不变,因为这是在不安全层中操作,那里可能会发生错误。
所以,Rust 提供了 unsafe 关键字和unsafe块,显式地将安全代码和访问外部接口的不安全代码进行了区分,也为开发者调试错误提供了方便。Safe Rust 表示开发者将信任编译器能够在编译时保证安全,而 Unsafe Rust 表示让编译器信任开发者有能力保证安全。
有人的地方就有 Bug。Rust 语言通过精致的设计,将机器可以检查控制的部分都交给编译器来执行,而将机器无法控制的部分交给开发者自己来执行。
Safe Rust 保证的是编译器在编译时最大化地保障内存安全,阻止未定义行为的发生。
Unsafe Rust 用来提醒开发者,此时开发的代码有可能引起未定义行为,请谨慎!人和编译器共享同一个“安全模型”,相互信任,彼此和谐,以此来最大化地消除人产生 Bug 的可能。
Unsafe Rust,是 Rust 的安全边界。世界的本质就是 Unsafe 的。你无法避免它。还有人说,因为 Unsafe Rust 的存在,所以也不见得能比 C/C++安全到哪里去?Unsafe Rust 确实和 C/C++一样,要靠人来保证它的安全。但它对人的要求更高。
它也给了开发者一个 Unsafe 的边界,这其实也是一种安全边界。它把你代码里的雷区,显式地标记了出来。团队代码里 review 的话,可以更快地发现问题。这本身就是一种安全。而反观 C++,你写出的每一行代码都是 Unsafe 的,因为它没有像 Rust 这样明显的界限(Unsafe 块)。
以下是我总结的五条使用 Unsafe 的简单规范,方便大家做权衡:
能用 Safe Rust 就用 Safe Rust;
为了性能可以使用 Unsafe Rust;
在使用 Unsafe Rust 的时候确保不要产生 UB,并且尽量判断其安全边界,抽象为 Safe 方法;
如果无法抽象为 Safe,需要标注为 Unsafe,并配以产生 UB 的条件文档;
对于 Unsafe 的代码,大家可以重点 review。
所以,Unsafe 使用不当也会引发内存安全或逻辑 Bug 。所以,学习 如何对 Unsafe Rust 进行安全抽象至关重要。
不过,Rust 社区生态中有一个 Rust 安全工作组,该组提供 cargo-audit等一系列工具,并且维护RustSecurity 安全数据库库中记录的Rust生态社区中发现的安全问题。可以方便地检查 Rust 项目中依赖库的安全问题。
生产力
编程语言生产力,大概可以通过以下三个方面来评估:
学习曲线。
语言工程能力。
领域生态。
学习曲线
学习曲线的高低,依个人水平不同而不同。以下罗列了不同基础学习 Rust 应该注意的地方。
完全零基础的开发者:掌握计算机基础体系知识结构,理解 Rust 语言和硬件/OS 层的抽象,理解 Rust 语言核心概念、以及它的抽象模式,选择 Rust 语言的某个适用领域进行实操训练,通过实践来提升 Rust 语言的熟练度和理解深度,同时掌握领域知识。
有 C 语言基础:由于 C 语言开发者对高级语言的抽象不是很理解,所以着重了解掌握 Rust 所有权机制,包括所有权的语义,生命周期和借用检查。了解 Rust 语言的抽象模式,主要是类型和 trait;以及 Rust 本身的的 OOP 和函数式语言特性。
有 C++基础:C++开发者对于 Rust 语言的所有权有很好的理解能力,主要精力放在 Rust 的抽象模式和函数式语言特性上。
有 Java/Python/Ruby 基础:着重理解攻克 Rust 所有权机制、抽象模式、函数式编程语言特性。
有 Go 基础:Go 语言开发者比较容易理解 Rust 的类型和 trait 抽象模式,但 Go 也是 GC 语言,所以所有权机制和函数式语言特性是他们的学习重点。
有 Haskell 基础:Haskell 系的开发者对 Rust 语言函数式特性能很好的理解,主要攻克所有权机制和 OOP 语言特性。
所以,对于有一定基础的开发者来说,学习 Rust 语言要掌握的几个关键概念有:
1、Rust 所有权机制,包括所有权的语义,生命周期和借用检查
所有权机制是 Rust 语言最核心的特性,它保证了在没有垃圾回收机制下的内存安全,所以对于习惯了 GC 的开发者,理解 Rust 的所有权是最关键的一环,切记这三点:
Rust 中的每一个值都有一个被称为其所有者 (owner)的变量。
值有且只有一个所有者。
当所有者(变量)离开作用域,这个值将被丢弃。这其中又涉及到生命周期和借用检查等概念,是相对比较难啃的一块硬骨头。
2、Rust 语言的抽象模式,主要是类型和 trait。trait 借鉴了 Haskell 中的 Typeclass,它是对类型行为的抽象,可以通俗地类比为其他编程语言里的接口,它告诉编译器一个类型必须提供哪些功能语言特性。使用时要遵循一致性,不能定义相互冲突的实现。
3、OOP 语言特性。熟悉面向对象编程(OOP)的常见的四个特性:对象、封装、继承和多态,可以更好地理解 Rust 的一些特性,比如 impl、pub、trait 等等。
4、函数式语言特性。Rust 语言的设计深受函数式编程的影响,看到函数式特性,数学不好的人可能会望而却步,因为函数式编程语言的最大特点是把运算过程尽量写成一系列嵌套的函数调用,在 Rust 中,掌握闭包和迭代器是编写函数式语言风格的高性能 Rust 代码的重要一环。
语言工程能力
Rust 已经为开发工业级产品做足了准备。
为了保证安全性,Rust 引入了强大的类型系统和所有权系统,不仅保证内存安全,还保证了并发安全,同时还不会牺牲性能。
为了保证支持硬实时系统,Rust 从 C++那里借鉴了确定性析构、RAII 和智能指针,用于自动化地、确定性地管理内存,从而避免了 GC 的引入,因而就不会有“世界暂停”的问题了。这几项虽然借鉴自 C++,但是使用起来比 C++更加简洁。
为了保证程序的健壮性,Rust 重新审视了错误处理机制。日常开发中一般有三类非正常情况:失败、错误和异常。但是像 C 语言这种面向过程的语言,开发者只能通过返回值、goto 等语句进行错误处理,并且没有统一的错误处理机制。而 C++和 Java 这种高级语言虽然引入了异常处理机制,但没有专门提供能够有效区分正常逻辑和错误逻辑的语法,而只是统一全局进行处理,导致开发者只能将所有的非正常情况都当作异常去处理,这样不利于健壮系统的开发。并且异常处理还会带来比较大的性能开销。
Rust 语言针对这三类非正常情况分别提供了专门的处理方式,让开发者可以分情况去选择。
对于失败的情况,可以使用断言工具。
对于错误,Rust 提供了基于返回值的分层错误处理方式,比如 Option 可以用来处理可能存在空值的情况,而 Result 就专门用来处理可以被合理解决并需要传播的错误。
对于异常,Rust 将其看作无法被合理解决的问题,提供了线程恐慌机制,在发生异常的时候,线程可以安全地退出。
通过这样精致的设计,开发者就可以从更细的粒度上对非正常情况进行合理处理,最终编写出更加健壮的系统。
为了提供灵活的架构能力,Rust 使用 特质(trait) 来作为零成本抽象的基础。特质 面向组合而非继承,让开发者可以灵活地架构 紧耦合 和 松耦合的系统。Rust 也提供了 泛型 来表达类型抽象,结合 trait 特性,让 Rust 拥有静态多态 和 代码复用 的能力。泛型和 trait 让你可以灵活使用各种设计模式来对系统架构进行重塑。
为了提供强大的语言扩展能力和开发效率,Rust 引入了基于宏的元编程机制。Rust 提供了两种宏,分别是声明宏和过程宏。声明宏的形式和 C 的宏替换类似,区别在于 Rust 会对宏展开后的代码进行检查,在安全方面更有优势。过程宏则让 Rust 在代码复用、代码生成拥有强大的能力。
为了和现有的生态系统良好地集成,Rust 支持非常方便且零成本的 FFI 机制,兼容 C-ABI,并且从语言架构层面上将 Rust 语言分成 Safe Rust 和 Unsafe Rust 两部分。其中 Unsafe Rust 专门和外部系统打交道,比如操作系统内核。之所以这样划分,是因为 Rust 编译器的检查和跟踪是有能力范围的,它不可能检查到外部其他语言接口的安全状态,所以只能靠开发者自己来保证安全。Unsafe Rust 提供了 unsafe 关键字和 unsafe 块,显式地将安全代码和访问外部接口的不安全代码进行了区分,也为开发者调试错误提供了方便。Safe Rust 表示开发者将信任编译器能够在编译时保证安全,而 Unsafe Rust 表示让编译器信任开发者有能力保证安全。
有人的地方就有 Bug。Rust 语言通过精致的设计,将机器可以检查控制的部分都交给编译器来执行,而将机器无法控制的部分交给开发者自己来执行。Safe Rust 保证的是编译器在编译时最大化地保障内存安全,阻止未定义行为的发生。Unsafe Rust 用来提醒开发者,此时开发的代码有可能引起未定义行为,请谨慎!人和编译器共享同一个“安全模型”,相互信任,彼此和谐,以此来最大化地消除人产生 Bug 的可能。
为了让开发者更方便地相互协作,Rust 提供了非常好用的包管理器Cargo。Rust 代码是以包(crate)为编译和分发单位的,Cargo 提供了很多命令,方便开发者创建、构建、分发、管理自己的包。Cargo 也提供插件机制,方便开发者编写自定义的插件,来满足更多的需求。比如官方提供的 rustfmt 和 clippy 工具,分别可以用于自动格式化代码和发现代码中的“坏味道”。再比如,rustfix 工具甚至可以帮助开发者根据编译器的建议自动修复出错的代码。Cargo 还天生拥抱开源社区和 Git,支持将写好的包一键发布到 crates.io 网站,供其他人使用。
为了方便开发者学习 Rust,Rust 官方团队做出了如下努力:
独立出专门的社区工作组,编写官方 Rust Book,以及其他各种不同深度的文档,比如编译器文档、nomicon book 等。甚至组织免费的社区教学活动 Rust Bridge,大力鼓励社区博客写作,等等。
Rust 语言的文档支持 Markdown 格式,因此 Rust 标准库文档表现力丰富。生态系统内很多第三方包的文档的表现力也同样得以提升。
提供了非常好用的在线 Playground 工具,供开发者学习、使用和分享代码。
Rust 语言很早就实现了自举,方便学习者通过阅读源码了解其内部机制,甚至参与贡献。
Rust 核心团队一直在不断改进 Rust,致力于提升 Rust 的友好度,极力降低初学者的心智负担,减缓学习曲线。比如引入 NLL 特性来改进借用检查系统,使得开发者可以编写更加符合直觉的代码。
虽然从 Haskell 那里借鉴了很多类型系统相关的内容,但是 Rust 团队在设计和宣传语言特性的时候,会特意地去学术化,让 Rust 的概念更加亲民。
在类型系统基础上提供了混合编程范式的支持,提供了强大而简洁的抽象表达能力,极大地提升了开发者的开发效率。
提供更加严格且智能的编译器。基于类型系统,编译器可以严格地检查代码中隐藏的问题。Rust 官方团队还在不断优化编译器的诊断信息,使得开发者可以更加轻松地定位错误,并快速理解错误发生的原因。
为了方便 Rust 开发者提升开发效率,Rust 社区还提供了强大的 IDE 支持。VSCode/Vim/Emacs + Rust Analyzer 成为了 Rust 开发的标配。当然 JetBrains 家族的 IDEA/ Clion 也对 Rust 支持十分强力。
Rust 与 开源
Rust 语言自身作为一个开源项目,也是现代开源软件中的一颗璀璨的明珠。
在 Rust 之前诞生的所有语言,都仅仅用于商用开发,但是 Rust 语言改变了这一状况。对于 Rust 语言来说,Rust 开源社区也是语言的一部分。同时,Rust 语言也是属于社区的。
Rust 团队由 Mozilla 和非 Mozilla 成员组成,至今 Rust 项目贡献者已经超过了 1900 人。Rust 团队分为核心组和其他领域工作组,针对 Rust 2018 的目标,Rust 团队被分为了嵌入式工作组、CLI 工作组、网络工作组以及 WebAssembly 工作组,另外还有生态系统工作组和社区工作组等。
这些领域中的设计都会先经过一个 RFC 流程,对于一些不需要经过 RFC 流程的更改,只需要给 Rust 项目库提交 Pull Request 即可。所有过程都是对社区透明的,并且贡献者都可参与评审,当然,最终决策权归核心组及相关领域工作组所有。后面为了精简 FCP 流程,也引入了 MCP。
Rust 团队维护三个发行分支:稳定版(Stable)、测试版(Beta)和开发版(Nightly)。**其中稳定版和测试版每 6 周发布一次。标记为不稳定(Unstable)和特性开关(Feature Gate)的语言特性或标准库特性只能在开发版中使用。
在 Rust 基金会成立以后,Rust 团队也在不断探索新的开源治理方案。
Rust 语言的不足
Rust 虽然有很多优势,但肯定也存在一些缺点。
Rust 编译速度很慢。虽然 Rust 官方也一直在改进 Rust 编译速度,包括增量编译支持,引入新的编译后端( cranelift ),并行编译等措施,但还是慢。而且 增量编译目前也有 Bug。
学习曲线陡峭。
IDE 支持不够完善。比如,对宏代码的支持不是很好。
缺乏针对 Rust 语言特有内存不安全问题的各种检测工具。
针对某些场景、架构和硬件生态支持不是很完善,这其实是需要投入人力和硬件成本来支持了,需要社区和生态的共同努力。
Rust 生态基础库和工具链
Rust 生态日趋丰富,很多基础库和框架都会以 包(crate) 的方式发布到 crates.io ,截止目前,crates.io 上面已经有 62981 个 crate,总下载量已经达到 7,654,973,261 次。
按包的使用场景分类,Crates.io 最流行的几个场景依次如下:
命令行工具 (3133 crates)
no-std 库 (2778 crates)
开发工具(测试/ debug/linting/性能检测等, 2652 crates)
Web 编程 (1776 crates)
API 绑定 (方便 Rust 使用的特定 api 包装,比如 http api、ffi 相关 api 等,1738 crates)
网络编程 (1615 crates)
数据结构 (1572 crates)
嵌入式开发 (1508 crates)
加密技术(1498 crates)
异步开发(1487 crates)
算法 (1200 crates)
科学计算(包括物理、生物、化学、地理、机器学习等,1100 crates)
除此之外,还有 WebAssembly 、编码、文本处理、并发、GUI、游戏引擎、可视化、模版引擎、解析器、操作系统绑定 等其他分类,也有不少库。
常用知名基础库和工具链
其中已经涌现出不少优秀的基础库,都可以在 crates.io 首页里看到。这里罗列出一些:
序列化/反序列化:Serde
异步/Web/网络开发: tokio / tracing /async-trait / tower / async-std tonic / actix-web /smol / surf / async-graphql / warp / tungstenite / encoding_rs / loom / Rocket
FFi 开发: libc / winapi / bindgen / pyo3 / num_enum / jni / rustler_sys/ cxx / cbindgen / autocxx-bindgen
API 开发: jsonwebtoken / validator / tarpc / nats / tonic/ protobuf / hyper / httparse / reqwest / url
密码学: openssl / ring / hmac / rustls / orion / themis / RustCrypto
WebAssembly: wasm-bindgen/ wasmer / wasmtime / yew
数据库开发: diesel / sqlx / rocksdb / mysql / elasticsearch / rbatis
并发:crossbeam / parking_lot / crossbeam-channel / rayon / concurrent-queue/ threadpool / flume
嵌入式开发:embedded-hal / cortex-m / bitvec / cortex-m-rtic / embedded-dma / cross / Knurling Tools
测试:static_assertions / difference / quickcheck / arbitrary / mockall / criterion / proptest / tarpaulin/ fake-rs
多媒体开发: rust-av/ image/ svg / rusty_ffmpeg/ Symphonia/
游戏引擎和基础组件:glam / sdl2 / bevy / amethyst/ laminar/ ggez / tetra/ hecs/ simdeez/ rg3d / [rapier](https://github.com/dimforge/ra pier) / Rustcraft Nestadia/ naga/ Bevy Retro/ Texture Generator / building_blocks / rpg-cli / macroquad
TUI/GUI 开发:winit / gtk / egui / imgui / yew / cursive / iced / fontdue / tauri / druid


